When patches replaced pixels: how Transformers took over computer vision
For the better part of a decade, computer vision has run on a single assumption: that the convolutional neural network is the right architectural prior for images. Convolutions bake in locality, translation equivariance, and a hierarchy of receptive fields, priors that match what we know about natural images. The results showed it, with ResNet, EfficientNet, and a long line of CNN descendants taking turns at the top of ImageNet. Then, on 22 October 2020, a team at Google Research posted a paper that asked whether any of that was necessary.
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" turned a long-running curiosity about applying self-attention to images into a credible, scalable alternative. After its ICLR 2021 presentation earlier this month, the paper is now the most discussed architectural argument in vision this year. The finding is simple: a vanilla Transformer, fed sequences of image patches and given enough pre-training data, matches or beats the best convolutional baselines while requiring less compute. Scale does the heavy lifting; convolution is optional.
This briefing walks through what the paper proposes, why it works (and when it doesn't), and what it means for the year ahead.
The paper at a glance
- arXiv ID: 2010.11929
- Title: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Authors: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
- Institution: Google Research, Brain Team
- Venue: ICLR 2021 (presented early May 2021)
- Submission date: October 22, 2020
- Source: arXiv:2010.11929
The long shadow of the convolutional prior
To understand what ViT is doing, it helps to remember where the field has been. Convolutional networks are an inductive bias tailored to images. Local kernels, weight sharing across positions, and stacked pooling operations build up translation equivariance and a multi-scale view of the world as side effects of the architecture. For years, this prior was so effective that the central questions in vision research were about depth, width, normalization, residual connections, and the rest of the CNN design vocabulary.
In parallel, the Transformer had taken over natural language processing. Self-attention, with its global receptive field and clean sequence-to-sequence interface, became the default for translation, language modeling, question answering, and most other text tasks. A few vision researchers tried to bring attention into CNNs, replacing certain layers, augmenting convolutional features with attention modules, or hybridizing the two. Results were positive but bounded. No one had shown that a pure Transformer, with no convolutional backbone at all, could compete with the best CNNs on serious benchmarks.
ViT's framing sharpens the question. Rather than asking how attention can help CNNs, it asks whether attention alone is sufficient, given enough data and compute.
The core idea: an image is a sequence
The move in ViT is to stop treating an image as a grid of pixels and start treating it as a sequence of tokens. The recipe is short.
Take an image of size H by W with C channels. Divide it into a grid of non-overlapping square patches of size P by P. For a 224 by 224 image with P=16, that yields 196 patches, each covering 16 by 16 pixels. Flatten each patch into a vector, project it linearly to a fixed embedding dimension, and you have a sequence. Prepend a single learnable [class] token, borrowed from BERT's classification convention, and add 1D learnable positional embeddings so the encoder knows where each patch came from. Feed the resulting sequence of N+1 tokens through a standard Transformer encoder, the same kind used in NLP. The representation at the [class] token after the final layer is the image embedding; a small classification head turns it into a class prediction.
The list of vision-specific design decisions in this architecture is short: the patchification step and the positional embeddings. Everything else, the multi-head self-attention, the LayerNorms, the position-wise MLP blocks, the residual connections, is a near-direct port of Vaswani et al.'s original Transformer. There is no convolution anywhere in the model. No spatial pooling hierarchy. No hand-crafted translational symmetry. The only prior the model has about the structure of images is that the input is broken into patches, plus the learned positional signal.
Walking through the architecture
The components are worth pulling apart in more detail, because the paper's main contribution is the careful integration of pieces that already existed.
The patch embedding is the only place where the structure of a 2D image enters the model. Each patch is flattened and projected to a D-dimensional vector via a single linear layer. The output is a sequence of N embeddings, each of length D.
The [class] token is a learnable vector prepended to the patch sequence, making the input N+1 tokens. After the encoder, the state of this token is used as the image representation. This is a direct inheritance from BERT and is competitive with global average pooling of the patch representations, a variant added in the camera-ready appendix.
Positional embeddings are needed because self-attention is permutation-equivariant. The paper uses standard 1D learnable position embeddings. The authors tried 2D-aware variants and found no measurable benefit, a small but interesting result. The pre-trained position embeddings are bilinearly interpolated to handle different fine-tuning resolutions.
The Transformer encoder stacks L blocks. Each block consists of LayerNorm, multi-head self-attention, a residual connection, LayerNorm, a position-wise MLP (with GELU and a hidden size of 4D), and another residual connection. The variants reported in the paper are:
- ViT-B/16: 12 layers, 12 heads, 768 hidden dim, ~86M parameters
- ViT-L/16: 24 layers, 16 heads, 1024 hidden dim, ~307M parameters
- ViT-H/14: 32 layers, 16 heads, 1280 hidden dim, ~632M parameters
- A smaller ViT-B/32 is also reported, using 32 by 32 patches.
The classification head is a small MLP with one hidden layer during pre-training. During fine-tuning, it is replaced by a single linear layer. The MLP head is removed at fine-tuning time and a fresh zero-initialized linear layer is attached for the downstream task. The paper documents a global-average-pooling variant in the camera-ready appendix that performs comparably to the [class] token.
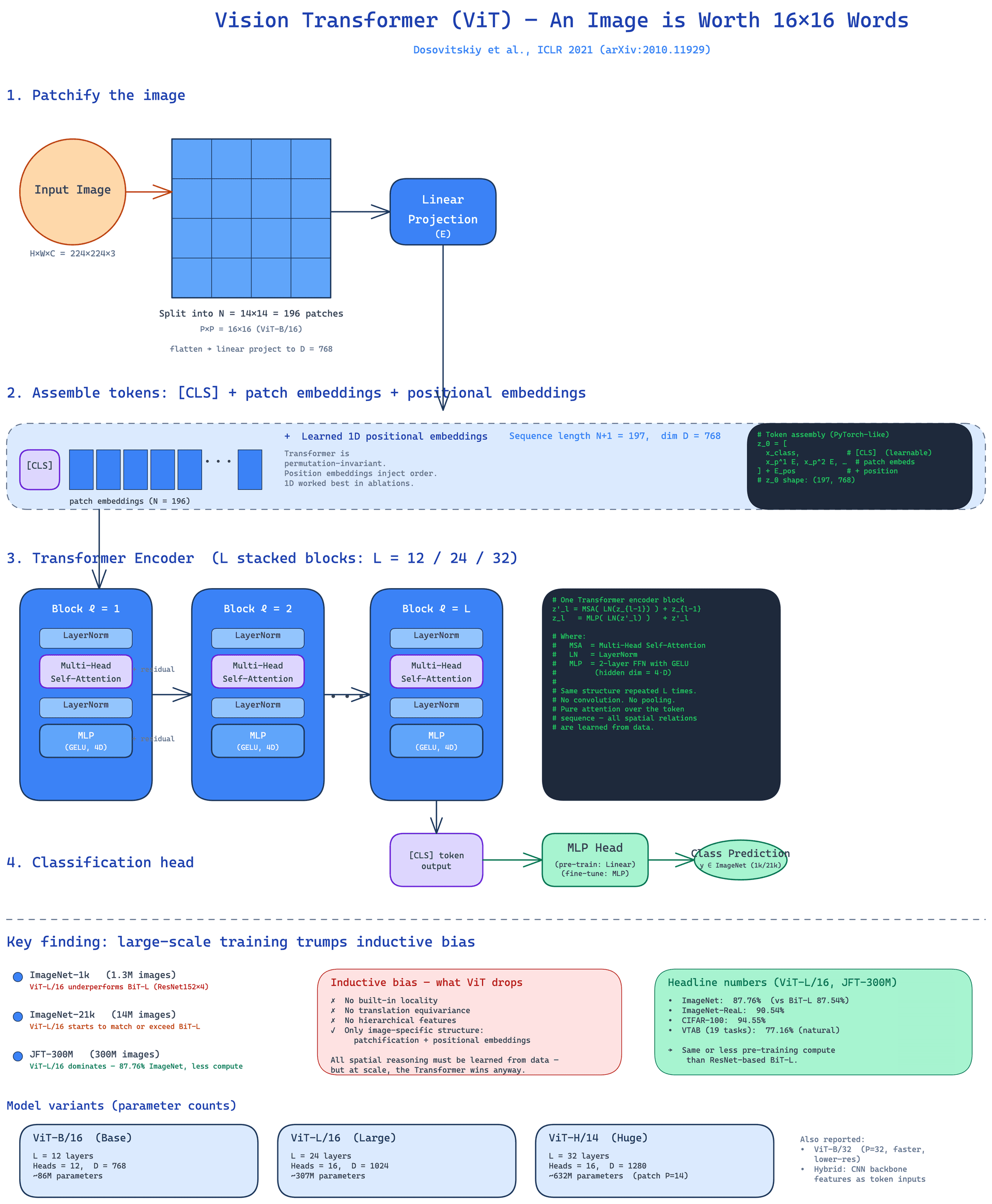
The diagram above traces the full pipeline: image to patches, patches to embeddings via a linear projection, [class] token prepended, positional embeddings added, the encoder stack applied, and the final [class] token's representation fed to the classification head. The only image-specific pieces are the patchification, the linear projection, and the learned positions; everything downstream is generic Transformer machinery.
What the experiments actually show
The paper's experimental design is built around a single axis: how does ViT behave as the pre-training data scale grows? The same architecture is pre-trained on ImageNet-1k (1k classes, 1.3M images), ImageNet-21k (21k classes, 14M images), and Google's internal JFT-300M (18k classes, 303M high-resolution images), then fine-tuned on a standard set of downstream benchmarks including ImageNet, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102, and the 19-task VTAB suite.
On ImageNet-1k alone, ViT underperforms. A ViT-L/16 trained only on ImageNet-1k does worse than a similarly sized ResNet. The explanation is intuitive: without enough pre-training data, the Transformer's lack of locality and translation-equivariance priors is a liability. The model has to learn spatial structure from data, and it does not have enough of it.
On ImageNet-21k and JFT-300M, ViT catches up and overtakes. With JFT-300M pre-training, ViT-L/16 hits 87.76% top-1 on ImageNet after fine-tuning at 384 by 384 resolution, beating the strong BiT-L (ResNet152x4) baseline at 87.54% on the same evaluation. On ImageNet-ReaL the same model reaches 90.54%, on CIFAR-100 it reaches 93.90%, and on the 19-task VTAB suite it reaches 76.28%, beating BiT-L on every dataset. The larger ViT-H/14 pushes these numbers further: 88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55% on CIFAR-100, and 77.63% on VTAB, with a reported 90.72% on ImageNet-ReaL being the best result in the paper.
Compute efficiency is a real result. The compute-versus-accuracy Pareto frontier of ViT sits below the BiT frontier. ViT uses approximately 2 to 4 times less compute to reach the same downstream performance, averaged over five datasets. This is the clearest empirical answer to the question of whether Transformers are competitive or actually superior at scale.
Scaling behavior mirrors NLP. Downstream accuracy improves smoothly as both model size and pre-training data grow. The larger ViT variants benefit more from additional pre-training data, the same kind of scaling pattern that has been documented in language Transformers.
Self-attention does what you would hope. An analysis of attention heads shows that lower layers attend broadly, with some heads looking across most of the image and others staying local, similar to the receptive-field expansion in early conv layers. Deeper layers attend more globally. Several heads in deeper layers focus a large fraction of their attention on the [class] token, which is consistent with the [class] token's role as a global image descriptor.
Self-supervision is a teaser, not a finish line. The paper includes a brief exploration of masked patch prediction, BERT-style pre-training adapted to image patches, on JFT-300M. With self-supervised pre-training, ViT-B/16 reaches 79.9% on ImageNet, a 2% improvement over training from scratch, but still about 4% behind supervised pre-training. The authors are explicit that this is preliminary.
The real lesson: large-scale training trumps inductive bias
Strip away the engineering and the paper makes one substantive claim: at sufficient scale, the carefully chosen inductive bias of convolutions is no longer the dominant factor in model quality. A model with no built-in notion of locality or translation, given enough pre-training data, learns to be at least as good at vision as a model that starts with those priors built in. The community shorthand for this is "large scale training trumps inductive bias," which is the line the authors actually use.
This is not an argument against CNNs in all settings. ViT's compute-versus-accuracy advantage is most pronounced at large pre-training scales; on smaller datasets the convolutional prior still pays for itself. But it reframes what counts as the limiting factor in vision. For several years, the community debate was about which architectural inductive bias to add: depthwise separable convolutions, grouped convolutions, squeeze-and-excitation, octave convolutions, and so on. ViT suggests that, at least for a class of problems, you can give up on the inductive bias debate and pour the compute into data and parameters instead.
The follow-on effect on the field has been fast. Within months of the preprint, derivative models started appearing: DeiT (data-efficient image Transformers, late 2020), T2T-ViT (tokens-to-token ViT, January 2021), PVT (pyramid vision Transformer, February 2021), DeepViT (March 2021), Swin (hierarchical ViT with shifted windows, March 2021), and DINO (self-supervised ViT, April-May 2021). All of them trace their lineage back to the patch-tokenization-plus-Transformer-encoder template ViT established.
Limits, risks, and what is open
The paper is honest about what ViT does not yet give you.
Data hunger is the central constraint. The headline numbers all assume pre-training on JFT-300M, a dataset that is not publicly available. Models trained on ImageNet-1k or ImageNet-21k do not consistently beat strong CNN baselines. The practical recipe is: pre-train on a giant private corpus, then transfer. The data-efficient variants (DeiT in particular) explicitly try to close this gap, but the original ViT paper does not pretend to solve it.
The inductive bias has to be learned, not given. ViT must discover locality, translation equivariance, and multi-scale structure from data. The attention-distance analysis shows it does so, but only after enough pre-training. Smaller pre-training corpora do not give it that chance.
Fine-tuning cost grows with resolution. Because the number of tokens is quadratic in the linear resolution for a fixed patch size, moving from 224 by 224 to 384 by 384 increases the sequence length by roughly a factor of three in each dimension, and attention cost grows accordingly. This matters for downstream tasks that require high-resolution input.
Positional embeddings need a hack at higher resolution. The learned 1D positional embeddings are bilinearly interpolated when the input resolution changes. It works, but it is the kind of detail that the convolutional world never had to think about.
Self-supervision is unresolved. The masked-patch experiments are described as preliminary, and self-supervised ViT-B/16 still sits 4% behind supervised pre-training. Whether the right self-supervised objective for ViT is masked patch prediction, contrastive learning, or something else, remains an open question, with active research underway in the community.
The hybrid question is mostly unanswered. The paper briefly discusses feeding ResNet intermediate feature maps to a Transformer encoder, but does not run a serious ablation. The relative merits of pure ViT, hybrid models, and the emerging hierarchical variants (Swin, PVT) are still being worked out.
For practitioners, the practical answer today is: if you have a large pre-training corpus and a clean fine-tuning task, ViT (or one of its derivatives) is a strong default. If you have a small dataset and a tight compute budget, a well-tuned CNN like EfficientNet is still in the running.
Where the field goes from here
The ViT paper has already changed the shape of vision research in concrete ways. Three directions look like they will define the next year.
Closing the data gap. DeiT, DINO, and a stream of follow-ups are explicitly trying to make ViT-style training feasible on smaller corpora, either through better training recipes, stronger data augmentation, or self-supervised pre-training. The most practically useful ViT descendant is likely to come from this direction.
Hierarchical and windowed attention. The original ViT keeps the full sequence length through the encoder, which is expensive at high resolution. Swin's shifted-window attention and PVT's pyramid structure reintroduce a kind of multi-scale hierarchy. Whether a pure global-attention ViT or a hierarchical variant wins at high resolution is unresolved.
Self-supervised ViT pre-training. The paper's preliminary masked-patch results hint at a self-supervised regime, but the real answer is still being searched for. DINO and related methods suggest self-supervision gives ViT properties that convnets do not have, but a clear winner has not emerged. Masked patch prediction, contrastive methods, and hybrid objectives are all being explored.
What ViT does is more important than any of these threads. It moves the conversation away from "which conv variant is best" and toward "what happens when we let a general-purpose sequence model learn visual structure from data." For a field that has spent a decade refining a single architectural template, that is a meaningful shift.
Sources
- Dosovitskiy et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," arXiv:2010.11929. https://arxiv.org/abs/2010.11929
- OpenReview entry (ICLR 2021). https://openreview.net/forum?id=YicbFdNTTy
- Reference implementation and pre-trained models. https://github.com/google-research/vision_transformer
- Vaswani et al., "Attention Is All You Need," the original Transformer. https://arxiv.org/abs/1706.03762
- He et al., "Deep Residual Learning for Image Recognition" (ResNet). https://arxiv.org/abs/1512.03385
- Kolesnikov et al., "Big Transfer (BiT): General Visual Representation Learning." https://arxiv.org/abs/1912.11370
- Tan and Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." https://arxiv.org/abs/1905.11946
- ICLR 2021 conference. https://iclr.cc/Conferences/2021