When the Comparison Tool Itself Is the Bug: A Dell Patent on Comparing Nested Data Without False Positives
Most software engineers have hit this one. A test compares two configuration objects, fails, and a careful read shows the two objects are functionally identical. The order of keys in a map is different, the order of items in a "set" is different, and the comparison library dutifully reports a difference that does not exist. The bug is not in the application code. It is in the comparison tool.
US patent 11,868,407, granted to Dell Products LP on January 9, 2024, and titled "Multi-level data structure comparison using commutative digesting for unordered data collections," is a small, focused patent that targets exactly that problem. Inventors Derek Labadie and Dominique Prunier describe a way to compare deeply nested data shapes, the kind of objects where dictionaries contain lists that contain other dictionaries, and so on, even when those objects mix ordered and unordered collections. The trick is not a better sort or a fancier diff algorithm. It is a choice of two different arithmetic operations inside the same recursive walk, picked per node based on whether the collection at that node cares about order. That single decision, repeated at every node of the tree, is the entire invention.
This is the kind of patent that tends to slip under the radar because the problem it solves is unglamorous. It is not a new database engine, not a new consensus protocol, not a new model architecture. It is a utility patent on a piece of test-harness plumbing. But the moment you ship a configuration system, a microservice that diffs incoming payloads, or a cache that only refreshes when the input changes, you are one re-shuffled JSON object away from needing it.
The patent at a glance
- Patent number: US 11,868,407 B2
- Title: "Multi-level data structure comparison using commutative digesting for unordered data collections"
- Assignee: Dell Products LP
- Inventors: Derek Labadie; Dominique Prunier
- Application number: US 17/030,500
- Filing date: September 24, 2020
- Pre-grant publication: US 2022/0092113 A1, March 24, 2022
- Grant date: January 9, 2024
- Adjusted expiration: June 19, 2041
- Status: Active
- Primary CPC classes: G06F 16/906 (clustering and classification), G06F 16/9027 (trees), G06F 16/80 (semi-structured data), G06F 16/90335 (query processing), G06F 7/02 (comparing digital values)
- Forward citations: 18 patents cited; 1 non-patent citation
- Source: Google Patents, https://patents.google.com/patent/US11868407B2/en
The case of the false-positive diff
The patent opens with a deceptively simple observation. The world runs on multi-level data structures: JSON, YAML, XML, nested objects in memory, config trees, response payloads. A multi-level data structure, in plain terms, is a data shape where each layer can hold more collections inside it. A single object may contain a list, and that list may contain other objects, each of which may contain yet more lists, and so on for several layers. Inside those structures, two flavors of collection live side by side. Ordered collections are sequences where position matters, the way the steps in a recipe matter. Unordered collections are sets, multisets, or maps where the order of elements has no meaning, the way the items in a grocery bag have no meaning. Formally, an unordered data collection is a group of elements in which swapping any two elements does not change the meaning of the collection, even though the bytes on disk might be different.
A great many comparison tools treat both kinds of collections the same way. They walk both structures in lockstep and compare the element at position i in one against the element at position i in the other. That is fast and simple. It is also wrong whenever the structures contain unordered collections. Two semantically identical bags, one of which happens to be iterated in a different order, will look different to a positional compare. The deeper the nesting, the worse this gets. Once you have lists of objects holding lists of sub-objects holding maps, sorting the structures into a canonical order before comparing them is no longer a quick fix. It is a corner-case mess that gets worse with every extra layer in between.
The patent calls this out directly: small data, you can sort; multi-level data, you cannot. The need it announces is for a comparison technique that knows the difference between collections that care about order and collections that do not, and that does not depend on the iteration order of the input.
Two accumulators, one walk
The core idea fits in one paragraph. For each node in the tree representation of a data structure, you compute a small fixed-size digest value, which is just a short, fixed-length "fingerprint" string that summarizes the contents of that node, much like a checksum does for a downloaded file. The digest function in the patent has the four classic properties a good hash needs: it is deterministic (the same input always gives the same output), quick to compute, has a strong avalanche effect (a property of good hash functions where any tiny change to the input flips roughly half the output bits, so a single altered character produces a wildly different fingerprint), and has very low collision probability (the chance that two different inputs accidentally produce the same fingerprint is astronomically small). The patent names MD5, SHA-1, and SHA-256 as concrete choices an implementer could plug in. It is not claiming a new hash function. The hash is a building block.
The novelty is in the next step. When you have a digest for every leaf, you walk up the tree and combine child digests into parent digests. The combining operation is chosen by the type of the node. If the node is an unordered collection, the children are combined with a commutative accumulator function, which simply means an arithmetic step where the order of the inputs does not matter, so a + b + c gives exactly the same result as c + b + a. The patent's primary worked example is scalar addition with overflow, which is commutative by construction. If the node is an ordered collection, or an individual key-value entry inside an object, the children are combined with a noncommutative accumulator function, the mirror image of the commutative case, where the order of the inputs absolutely changes the result. The patent mentions scalar division (its other worked example) and matrix multiplication as concrete noncommutative options. For scalar division, a / b is almost never equal to b / a, which is exactly the asymmetry we want for a sequence whose order carries meaning.
That asymmetry is the whole point. You want the digest of a sequence to be sensitive to its order, and you want the digest of a bag to be insensitive to its order. Choosing the right arithmetic at each node gives you both behaviors from a single recursive procedure.
A JSON-like object is handled as a small hybrid. The object itself is treated as an unordered collection of key-value entries, so the entries are folded with the commutative outer accumulator (reordering entries is fine). But each individual entry is folded with the noncommutative accumulator over the (key, value) pair, so swapping a key with its value inside an entry changes the digest. That is the right behavior: {name: "Alice"} and {name: "Alice"} should match; {name: "Alice"} and {Alice: "name"} should not.
The decision between commutative and noncommutative is not hard-coded into the type system. It is read from a configuration that is keyed off the path of the element in the tree, using a notation like JSONPath, which is a mini-language, similar in spirit to XPath for XML, that lets you write expressions like $.admins[*].objectives to address a specific location inside a nested JSON document. The same JSON blob can be compared under different "orderedness" assumptions in different parts of a product, simply by changing which paths are flagged as ordered.
The flow, from leaves to verdict
What you actually get, in concrete plumbing, is a tool with four cooperating modules. A Data Structure Comparison Module orchestrates the whole thing. A Digest Calculator Module runs the per-element hash. A Commutative Accumulator Module owns the fold for unordered collections. A Noncommutative Accumulator Module owns the fold for ordered collections and key-value pairs. The tool can be deployed three ways depending on the workload: on a dedicated comparison server, on a client device pulling structures from a backend, or as a library embedded inside an application server that needs to decide whether to trigger an expensive downstream recompute.
The pseudocode in the patent reads like a clean recursive descent with one extra parameter. You pass in the current element, its parent path, and a configuration object. If the element is a collection, you compute the current path, check the configuration, and pick the right accumulator. If the element is an object, you initialize a commutative accumulator over the entries. Then for each entry, you compute a noncommutative sub-fold over the (key, value) pair and feed that sub-fold into the outer commutative accumulator. If the element is a simple value, you hash it and return. The recursion bottoms out at the leaves and bubbles up to a single root digest per structure.
The comparison step itself is almost boring, which is the point. You compute one digest value for each structure. A digest value is that same fixed-length fingerprint of a piece of data, sized so the whole structure collapses into a single comparable number regardless of how deeply the data is nested. You compare them. Equal digests mean equal data, because a digest mismatch can only be produced by a difference somewhere in the structure, and the commutativity and noncommutativity choices ensure that semantically irrelevant reorderings do not flip the digest. Each digest is also built with the avalanche effect baked in, so even a one-character change anywhere in either structure will, with overwhelming probability, produce a different root digest, and the test is sensitive in both directions.
The diagram below traces the same flow at a glance.
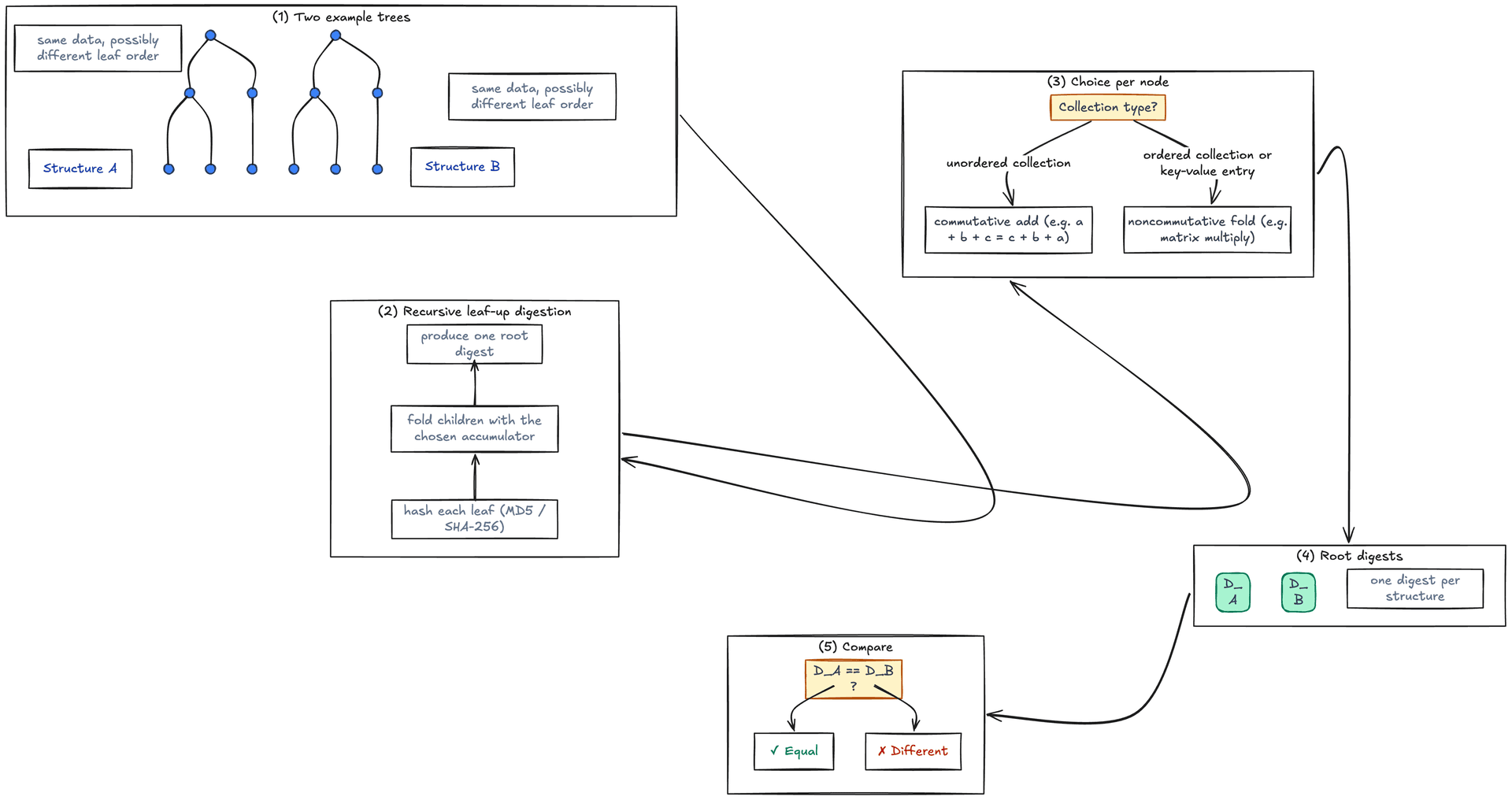
The visual argument has five beats, left to right. Two small trees stand in for the two input structures. A vertical spine reads bottom-up as the recursive leaf-to-root walk (hash, fold, root). A branching decision diamond is the patent's whole insight in one shape: the path through the tree forks based on whether the collection at the current node is ordered or unordered. The left fork (commutative add, where a + b + c = c + b + a) is what gives you reorder-stability for bags. The right fork (noncommutative fold, where order matters) is what gives you order-sensitivity for sequences. The two paths rejoin into two green digest ellipses, D_A and D_B, which feed a final comparison diamond that ends in a check for equal or a cross for different.
A worked example appears in the patent itself, using an "administrator" object that holds a name, an unordered list of managed systems, and an ordered list of objectives in priority order. Two administrators, Alice and Bob, have semantically identical structures whose internals differ only in iteration order. The same data is shown in four equivalent forms: an object diagram, a YAML serialization, a JSON serialization, and a tree. The patent walks the tree, hashes the leaves, folds the systems list commutatively, folds the objectives list noncommutatively, and produces a single root digest per administrator. Two administrators with the same digest are considered the same administrator.
What the claims actually cover
The patent has 20 claims organized in the classic three-for-one form: an independent method claim, an independent apparatus claim (a system with a processor and a memory), and an independent non-transitory computer-readable storage medium claim, each with a roughly parallel set of dependent claims underneath.
Claim 1, the recipe
The method claim lays out the recipe in five steps. First, obtain at least two multi-level data structures, at least one of which contains an unordered data collection. Second, for each structure, accumulate a per-element digest value, using a commutative accumulator function for unordered collections. Third, evaluate similarity by comparing the structure-level digests. Fourth and fifth, automatically process the structures using that evaluated similarity.
Claims 2 through 9, the small print
The dependent claims then narrow each piece of the recipe. Claim 2 pins down the property that makes the commutative accumulator function useful: it produces the same digest value for an unordered data collection regardless of iteration order. Claim 3 specifies that the structure-level digest value is built by recursive accumulation from the leaves up. Claims 4 and 5 cover the symmetric case: ordered collections and per-key-value-pair folds use a noncommutative accumulator function and a noncommutative operation. Claim 6 is the equality test in plain language: two multi-level data structures are equal when their digests match. Claim 7 names the configuration-driven path keying as the source of the ordered-vs-unordered decision, with paths expressed in JSONPath so a schema can declare $.admins[*].objectives as ordered and $.admins as unordered.
Claim 8 is where the practical payoff shows up. The downstream automatic processing covers (i) comparing computed data against expected data, (ii) detecting whether input data has changed, and (iii) triggering a heavy process or application only when a change is detected. Claim 9 lists the four digester properties the patent relies on, including the avalanche effect, which the patent describes as the digest changing significantly for any small change to the underlying data element. The apparatus and storage-medium claims (claims 10 and 15) mirror the method claim almost word-for-word, and their dependents re-cover the same ground in apparatus and storage-medium form.
If you wanted to design around this patent, the interesting targets are the path-keyed configuration claim (claim 7) and the leaf-up recursive construction claim (claim 3). Most of the rest reads as a straightforward recitation of a hash-and-fold scheme.
Why this matters in 2025
A patent like this matters for three different audiences in three different ways.
For application developers, the patent is a useful prior-art reference. If you have ever written, or considered writing, a deep-equal-style utility that can tell two deeply nested config objects apart without false positives on unordered bags, the patent gives you a defensible template. The hash-and-fold scheme is small enough to fit in a single file, and the trick of swapping the accumulator per node generalizes to any tree-shaped data you can serialize.
For platform owners, the patent's most useful claim is the one about gating expensive downstream processing on a change-detection signal. Cloud configuration services, secrets managers, content delivery networks, and feature-flag systems all want to avoid recomputing a derived artifact when the underlying input has not changed. The patent's D_A == D_B? test, in the form of a single digest value comparison, is exactly the cheap input to that decision. You rebuild the cache only when the digests diverge, and because of the avalanche effect, even a single-byte change to either input will, with overwhelming probability, cause the two root digest values to differ and trip the gate.
For the prior-art landscape, the patent is a baseline. A granted claim of this shape, in 2024, on commutative accumulator functions, path-keyed configuration via JSONPath, and recursive leaf-up construction over multi-level data structures, is the kind of reference that examiners and competitors will reach for in any later patent application that tries to claim the same ground. If you are filing in this neighborhood in 2025 or 2026, the file wrapper for application 17/030,500 on USPTO Patent Center is worth a careful read.
A small structural note on classification: the patent is classified under clustering and classification, query processing, and tree-structured data storage, which is where a tree-shaped digest scheme belongs. The "comparing digital values" classification (G06F 7/02) is the giveaway that the patent sees itself as a comparison technique, not a database invention.
The caveats worth flagging
A few honest limits.
The scheme tells you whether two multi-level data structures differ, not where they differ. A digest value mismatch is a yes-or-no signal, and pointing the developer at the specific element that changed is a separate problem that needs a separate tool. The patent is explicit about this. The digest is the input to a higher-level decision, not a replacement for a real diff.
The choice of commutative operation is not pinned down. The patent gives scalar addition with overflow as the commutative example, and scalar division and matrix multiplication as the noncommutative examples, but those are illustrative. In practice, you have to pick a commutative accumulator function whose range and collision behavior play well with the digest's output width. Pick a 256-bit digester and a 64-bit commutative accumulator, and you have collapsed your collision space. The patent does not save you from that mistake.
The unordered-vs-ordered decision is configuration-driven, which is both the scheme's main feature and its main footgun. A misconfigured schema will silently misclassify an ordered list as an unordered data collection, or vice versa, and produce wrong equality results with no error. Anyone who has debugged a system that depends on a config file being exactly right will recognize the failure mode. JSONPath makes the configuration expressive, but it also makes it easy to typo a path and silently flip the meaning of a node.
The patent's example workloads (testing and debugging, change detection, cache invalidation) are read-mostly. It does not by itself address streaming, incremental, or partially-shared substructure comparison, which a real production system would probably need to bolt on.
Finally, the patent's prosecution history, its forward-citation set, any continuation or divisional filings, and any foreign counterparts are not surfaced in the bibliographic record. Anyone doing freedom-to-operate work should pull the file wrapper for application 17/030,500 from USPTO Patent Center and check the forward citations on Google Patents before relying on this brief as a complete map of the surrounding prior art.
What to watch
Two things are worth keeping an eye on. First, follow-on filings: if Dell or its inventors extend the technique to streaming comparison, partial-substructure sharing, or signed digest trees, the dependent claims here will be the natural place to anchor those extensions. Second, prior-art reactions: if you see a 2025 or 2026 patent application on deep-equal or change-detection schemes for nested multi-level data structures that does not cite 11,868,407, the examiner may end up surfacing it during prosecution, and that application's claims will have to thread the needle around the commutative accumulator function and JSONPath-keyed configuration claim language.
That brings us back to the engineer who opened this piece: the one who wrote a test that compared two identical config objects and watched it fail on a phantom difference. The fix is small. Compute a digest, pick the right accumulator at every node, and let the commutative / noncommutative choice do the heavy lifting. The hard part, as always, is choosing the right commutative operation, picking a digester with a strong enough avalanche effect to make accidental collisions vanishingly unlikely, and getting the JSONPath configuration right for your own data model. Once those two are nailed down, the rest is mechanical.
Sources
- US Patent 11,868,407 B2: "Multi-level data structure comparison using commutative digesting for unordered data collections," inventors Derek Labadie and Dominique Prunier, assignee Dell Products LP, granted January 9, 2024. https://patents.google.com/patent/US11868407B2/en
- USPTO Patent Center record for application 17/030,500. https://patentcenter.uspto.gov/applications/17030500
- Espacenet record for US 11,868,407 B2. https://worldwide.espacenet.com/publicationDetails/biblio?CC=US&NR=11868407B2&KC=B2&FT=D
- Pre-grant publication US 2022/0092113 A1 (March 24, 2022), cited in the same Google Patents record.
- Cooperative Patent Classification scheme, class G06F (USPC/CPC reference). https://www.uspto.gov/web/patents/classification/cpc/html/cpc-G06F.html