The Web, with the Links Cut: How IPFS Wants to Replace HTTP at the Storage Layer
There is a quiet assumption baked into the modern web, so foundational that most engineers stop noticing it: when you fetch a file, you are fetching it from a place. You ask https://example.com/foo.png, and somewhere a single machine, or a small cluster, answers. If that machine disappears, the link rots. If the link is mistyped, you get nothing. If the dataset is terabytes large, you and the network and the origin server are all stuck doing the same dance every time. For thirty years, this has been fine. Now it is starting to creak.
This week's briefing looks at a paper that has been quietly nudging that assumption for the last half-decade. "IPFS — Content Addressed, Versioned, P2P File System," by Juan Benet, is the canonical specification for the InterPlanetary File System. The original preprint landed on arXiv in July 2014, and the project that grew out of it (Protocol Labs, Filecoin, a sprawling open-source stack) has spent the years since turning the paper's design into working infrastructure. The version on arXiv as of this month is the substantive one to read. It is also the most ambitious attempt I have come across at building one coherent answer to a specific question: what would the web look like if the URL were the hash of the file instead of the address of the server?
The paper at a glance
- Authors: Juan Benet (Protocol Labs).
- Title: IPFS — Content Addressed, Versioned, P2P File System.
- arXiv: arXiv:1407.3561 [cs.NI] (v1 submitted 14 July 2014; this briefing references the same v1).
- DOI: 10.48550/arXiv.1407.3561.
- Subjects: Networking and Internet Architecture (cs.NI); Distributed, Parallel, and Cluster Computing (cs.DC).
- Length: 11 pages in the arXiv PDF; the ar5iv HTML mirror runs to roughly 1,400 lines.
- License: Creative Commons Attribution 3.0.
- How to read it: skim Section 1 for the framing, then read Section 3 in order. Section 3.4 (BitSwap) and Section 3.5 (Object Merkle DAG) are where the actual ideas are.
The Web Was Never Designed for Petabytes
Benet's opening move is a small piece of historical accounting, and it is sharper than the usual "HTTP is old" hand-waving. Academic distributed filesystems from the 1980s and 1990s (AFS, CFS, OceanStore) had real wins inside their institutions but never escaped. The systems that actually got to hundreds of millions of users (Napster, KaZaA, BitTorrent) were not designed as general infrastructure; they were designed to move a specific kind of large file. BitTorrent in particular has been carrying a non-trivial fraction of internet traffic for more than a decade, and tens of millions of its nodes churn daily. There is no general-purpose, decentralized, low-latency filesystem sitting on top of that distribution capacity.
HTTP is, in his framing, the de facto distributed filesystem of the internet, and the one we keep using despite the cost. It cannot host petabyte datasets cheaply. It cannot let two organizations compute against a shared copy of large data without shipping the data first. It cannot stream high-definition media on demand without dedicated CDN capacity. It cannot keep a link alive when the original publisher goes away. This is the one he keeps coming back to: HTTP has no real answer for accidental disappearance. The 404 is not a bug. It is the natural state of a system that points to places instead of contents.
Git, he observes, already has a better data model: a Merkle DAG of immutable, content-addressed objects. The trouble is that nobody has ever built a high-throughput filesystem on top of that data structure and aimed it at the web.
One Merkle DAG to Bind Them
The structural claim of the paper is simple to state. Every piece of data in IPFS, every file, every chunk, every directory listing, every version, every record in every application anyone ever builds on top of it, is a node in the same directed acyclic graph. Each node carries a list of links, where every link is the cryptographic hash of another node. The address of a piece of data is its hash. Period. There is no global root, no namespace authority, no top-level directory that everyone agrees on. The root of any given subgraph is whatever commit you happen to start from.
This buys four properties at once, and the paper leans on all four.
Content addressing. Two nodes with the same content have the same hash. Dedup is automatic. Indexing is automatic. Caching is automatic.
Tamper resistance. Every block is verified by its hash on retrieval. A corrupted block is a hash mismatch, not a mystery.
Path resolution without a global root. A path is just a sequence of link names. /ipfs/<hash-of-foo>/bar/baz walks the link table of foo, fetches the object named bar, and walks its links to baz. If you know the hash of bar, you can address the same content as /ipfs/<hash-of-bar>/baz. If you know the hash of baz itself, you can skip the walk entirely. The paper's claim is that this lack of a root is a feature: a single global root would have to coordinate consistency across millions of nodes in a network that is allowed to be disconnected, and that coordination problem is the one we keep failing at.
Uniform data structures on top. The same IPFSLink { Name, Hash, Size } plus IPFSObject { links, data } pair can be used to build Git-like versioned filesystems, key-value stores, relational databases, linked data triple stores, and cryptocurrency blockchains. The paper presents this as future work, but the framing is that the data model is the primitive, and everything else is a convention on top of it.
The Seven-Layer Stack and Why Each Piece Has to Be There
The body of the paper walks through a seven-layer protocol stack. Most of the layers are not new inventions, and the paper admits it. In Benet's words, the contribution is "simplifying, evolving, and connecting proven techniques into a single cohesive system, greater than the sum of its parts." BitSwap is the one genuinely new layer; we will get to it. The rest are recognisable from other systems, which is the point.
Identities. A node is identified by a NodeId, which is a multihash of a public key, generated with S/Kademlia's static proof-of-work puzzle. The "hash of a hash" is deliberate: when two nodes meet, they can verify identity without trusting a certificate authority. Exchange public keys, check hash(other.PubKey) == other.NodeId, drop the connection if it does not match. Multihash itself is self-describing (a tiny header names the hash function and digest length), which means the system can change crypto choices without breaking existing references.
Network. Intentionally thin. WebRTC DataChannels for browser peers, uTP/LEDBAT for low-priority background transfer, SCTP for reliability, ICE for NAT traversal, multiaddr byte strings for addresses. Any of this is swappable.
Routing. This is where the paper reaches for Kademlia, Coral, and S/Kademlia and stitches them together. The interface is small: FindPeer, SetValue, GetValue, ProvideValue, FindValuePeers. Small values (≤ 1 KB) get stored directly in the DHT; bigger values get stored as references to peer NodeIds that can serve them. The Coral-style "sloppy get" (return any working peer, not the full set) is what keeps the system from melting when a key gets hot.
Exchange: BitSwap. This is the part of the paper that is not borrowed. BitSwap is a BitTorrent-inspired block-exchange protocol, but with one decisive change: the barter is not scoped to a single torrent. Every connected peer carries a want_list of blocks it needs and a have_list of blocks it can offer, and the barter crosses file boundaries. A node that has nothing any peer wants still seeks the blocks its peers want, at lower priority than its own wants. This is the explicit incentive to cache and disseminate rare pieces even when the node is not personally interested.
The credit system is the subtler trick. Each node keeps a per-peer ledger of bytes sent and bytes received. The probability of sending a block to a debtor is a sigmoid that falls sharply once the debt ratio crosses roughly 2:1:
This makes the function lenient to debts between nodes with a long shared history, and merciless to new, untrusted, or Sybil-suspect peers. Default timeouts are 10 seconds for an ignore_cooldown after a refused send and 30 seconds for silence_wait before a soft close. If the ledgers disagree on connect, both sides reset to zero, which means a malicious node can wipe its own debt by losing its ledger. The partner is free to count that as misconduct and refuse future trades.
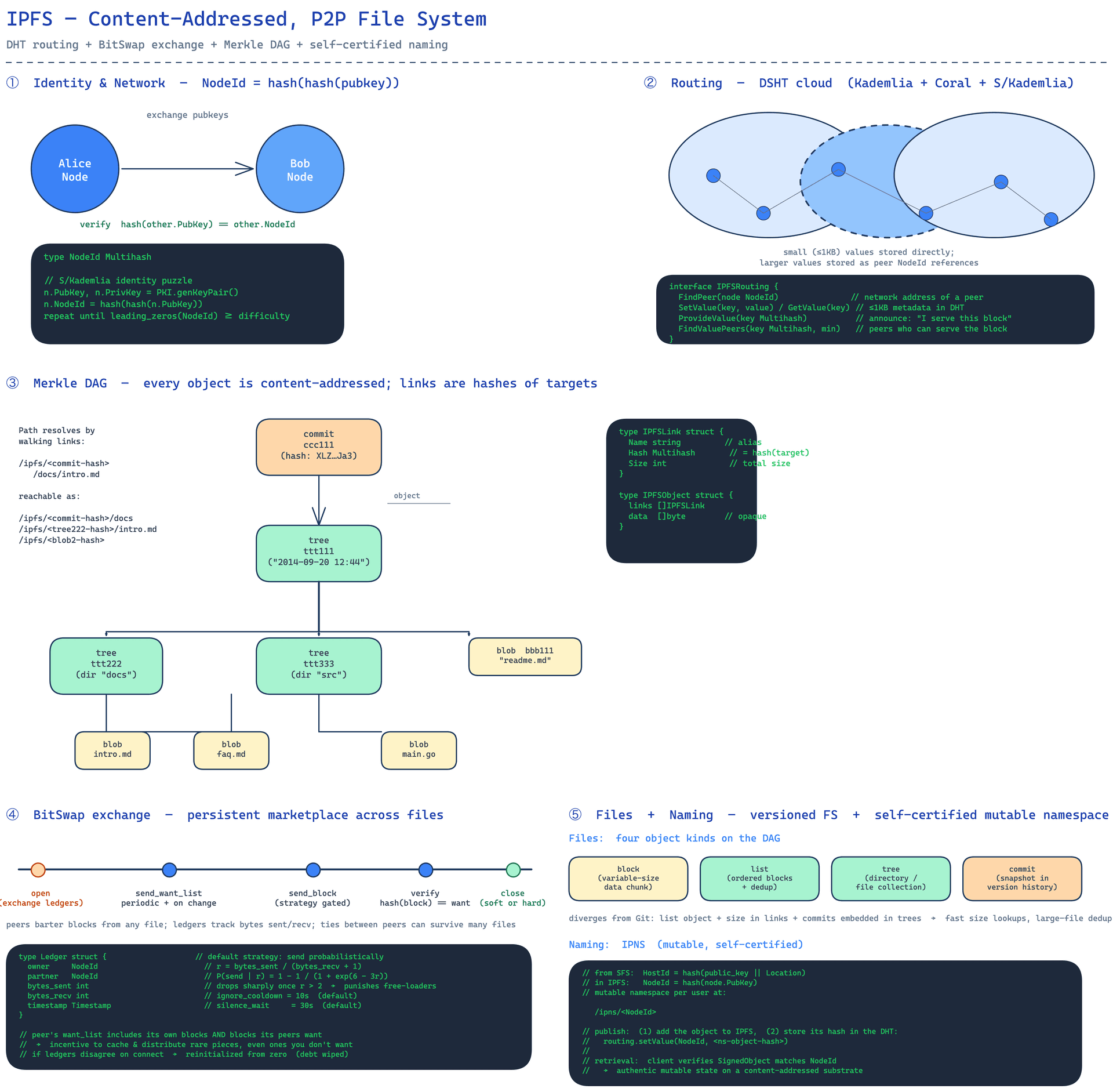
Objects, Files, Naming. The Merkle DAG sits on top. On top of that, a Git-like versioned filesystem with four object kinds (block, list, tree, commit), where the list object is the deliberate divergence from Git, added to make large-file deduplication and fast aggregate size lookups tractable. And on top of that, the naming layer. /ipfs/<hash> is the immutable path. /ipns/<NodeId> is the mutable one: every user has a self-certified namespace at her NodeId, and she publishes by writing her signed object to IPFS and then storing its hash in the DHT under her NodeId. The act of publishing is the act of giving a key to the DHT.
What the Paper Claims, and Where It Is Quiet
The paper is explicit about its contribution. Only one piece, BitSwap, is a novel protocol. The rest is synthesis, and the rest is a lot: Kademlia plus Coral plus S/Kademlia for routing, BitTorrent for block exchange with the cross-file twist, Git for the data model, SFS for the naming. The author makes the synthesis argument directly. The benefit, in his framing, is that the whole system becomes a single platform you can build on, not a tower of siloed protocols each of which solves a different piece of the problem.
Three concrete claims show up repeatedly and are worth holding onto.
- Single BitTorrent swarm, one Git repository. That is the one-line description. The point is composability: every block the system ever stores is a candidate peer-trade with every other block.
- Generalized Merkle DAG as the universal substrate. A blockchain is a Merkle DAG. A versioned filesystem is a Merkle DAG. A linked-data triple store is a Merkle DAG. The paper claims, as a research direction rather than a finished result, that IPFS can be the transport layer for all of them.
- No single point of failure, and no requirement that nodes trust each other. Because identity is self-certified and blocks are self-verifying, the system can tolerate a hostile majority as long as you can find at least one honest peer who has the block. (Caveat: the paper notes S/Kademlia's disjoint-path lookups, which keep correctness at 0.85 success even with 50% adversarial nodes. That is a hard bound, not a marketing number.)
The paper is quieter about a few things, and reading those silences is informative.
- Performance numbers are absent. No benchmark, no throughput chart, no latency table. The paper is a design document, not an evaluation. The "Permanent Web" framing is the design goal, not a measured result.
- The currency-and-incentives piece is explicitly future work. The barter system in BitSwap works when blocks are complementary, and degrades to "leechers must be punished by the credit function" when they are not. A virtual currency on top of BitSwap would require a global ledger, and the paper punts that to "a future paper," which is the direction Filecoin eventually went, but that is a separate story.
- The strategy space is wide open. The sigmoid is "one choice of function that works in practice." BitTorrent's own history (BitTyrant, BitThief, PropShare) is the warning shot. BitSwap inherits that open game-theoretic surface, and the paper says so.
Why It Matters Right Now
Four and a half years on, IPFS is one of those projects where the paper still matters because the architecture still matters. Every few months, a different application surfaces that turns out to be a Merkle DAG problem in disguise: package distribution, dataset versioning, scientific reproducibility, decentralized identity, content-addressed storage for edge networks. IPFS is the most-used general-purpose content-addressed store in the wild, and the most-used general-purpose peer-to-peer filesystem anyone has actually shipped. The reason is the design choice the paper commits to: when you point at hashes instead of hostnames, you get dedup, integrity, and a kind of permanence for free, and a lot of problems that look like distributed-systems problems turn out to be data-model problems.
What the paper does that is hard to replicate is treating the data model as the protocol. Most "decentralized storage" projects add a hash layer on top of an existing location-addressed system and call it a day. IPFS, in this paper, is the other way around. The Merkle DAG is the floor. Routing, exchange, and naming are what you build on top. That inversion is the idea worth taking seriously.
Limits, Risks, and What Is Still Open
The paper does not solve everything. Five things are worth being specific about.
- The discovery problem at internet scale. The DHT is fine for finding peers who have a known hash. It does not, by itself, solve the question of how a new node learns about popular content in the first place. Production deployments layer extra index and pinning services on top, and the paper does not pretend otherwise.
- Permanence is a community choice, not a protocol guarantee. Pinning is the mechanism by which a node chooses to keep a particular object (and, recursively, everything it links to) alive in its local storage. The "Permanent Web" only persists as long as somebody, somewhere, keeps pinning. There is no SLA.
- The credit system punishes strangers, which is also how Sybil resistance works. The sigmoid is the right shape for the trust curve, but it is a bet about the population of peers. A network where most peers are honest looks very different from one where most peers are new.
- Crypto agility is a promise, not a delivery. Multihash lets the system name its hash functions, which means a transition to a post-quantum or a faster function is possible without breaking references. The transition itself, and the migration of a live network to a new hash, is unsolved.
- No benchmarks. Treat the design arguments at face value. The paper does not show you that the system is fast; it shows you why, if it works as designed, it would be the right shape.
In short: the paper is mostly right about the architecture, mostly right about the limits it admits, and mostly quiet about the limits it does not. Read it for the data model and the protocol stack. Read the implementation if you want to know what actually shipped. And read the Filecoin papers if you want to know what the open game-theoretic questions look like once you try to put a market on top.
Sources
- Juan Benet, IPFS — Content Addressed, Versioned, P2P File System, arXiv:1407.3561 [cs.NI], submitted 14 July 2014. https://arxiv.org/abs/1407.3561 · DOI 10.48550/arXiv.1407.3561 · full text https://ar5iv.labs.arxiv.org/html/1407.3561
- Submission metadata and DOI via DataCite: https://doi.org/10.48550/arXiv.1407.3561
- Cited background papers inside the IPFS paper: Maymounkov and Mazieres, Kademlia: A peer-to-peer information system based on the xor metric (2002); Baumgart and Mies, S/Kademlia (2007); Freedman, Freudenthal, and Mazieres, Democratizing content publication with Coral (NSDI 2004); Cohen, Incentives build robustness in BitTorrent (2003); Mazieres and Kaashoek, Self-certifying file systems (1998, 2000); Wang and Kangasharju, Measuring large-scale distributed systems: case of BitTorrent Mainline DHT (IEEE P2P 2013).