The quiet trick that lets a cloud server run a program it cannot read
If you have ever sent a sensitive document to a cloud service, you know the small chill of handing over your data. Fully homomorphic encryption is the idea that says you should not have to. A server with a fully homomorphic scheme can run any program on your encrypted data. It ships you an encrypted result without ever learning the plaintext. The catch, for a long time, was the "fully" part. Craig Gentry's original 2009 construction was theoretical and slow. Fifteen years later, the idea is starting to look like infrastructure.
This explainer walks through the FHE idea from the bottom up, with the noise budget and Gentry's bootstrapping trick in plain terms. No new patent or paper drives the framing here. Recent public discussion in cryptographer communities on the r/cryptography subreddit treats FHE as something the field is still teaching itself. That turns out to be a useful lens. The idea is not new, the curve to understand it is real, and the engineering maturity is uneven. The diagram at the end is the part worth saving.
Briefing registry
- Topic: fully homomorphic encryption, its mechanism, and the bootstrapping step that makes arbitrary computation possible
- Source basis: a recent r/cryptography thread on learning FHE, public cryptographic literature, and the standard references on lattice-based FHE schemes (BGV, BFV, CKKS, TFHE)
- Type: conceptual explainer, not a single paper or patent
- Date: June 10, 2026
A strange word for "it computes on encrypted data"
A homomorphic encryption scheme is one where you can compute on the ciphertext. Add two ciphertexts and you get a new ciphertext that, when decrypted, equals the sum of the plaintexts. Multiply two ciphertexts and you get a ciphertext that decrypts to the product. If the scheme supports arbitrary additions and multiplications, it supports any Boolean or arithmetic circuit. That is the same thing as saying it supports any program.
There is a hierarchy. A partially homomorphic scheme supports one operation forever. RSA is multiplicatively homomorphic, so Enc(m1) times Enc(m2) decrypts to m1 times m2. Paillier is additively homomorphic, so Enc(m1) plus Enc(m2) decrypts to m1 plus m2. These are useful and have been deployed for decades in specific places, like electronic voting and private aggregation. A somewhat homomorphic scheme supports both operations, but only up to a bounded depth before the math breaks. A fully homomorphic scheme supports both operations to arbitrary depth, which is what people usually mean when they say FHE.
The "fully" part is what took forty years to get right.
Why naive LWE schemes stop working after a few multiplications
Modern FHE schemes are built on the Learning With Errors (LWE) hardness assumption and its ring variant, RLWE. Both rely on lattices. Both have post-quantum security. Together, they are the reason homomorphic encryption has become a credible way to protect data in use. The trade is that every ciphertext carries a small amount of random noise. The noise is what makes LWE hard, and the noise is also what limits the scheme.
When you add two ciphertexts, the noise adds. When you multiply two ciphertexts, the noise multiplies, and in practice it grows even faster because of relinearization overhead. After enough operations, the noise in the ciphertext becomes comparable to the message itself, and decryption starts returning the wrong answer. The scheme breaks.
A naive FHE scheme built directly on LWE is therefore only "somewhat" homomorphic. It can evaluate a circuit of bounded multiplicative depth. Bounded depth is the whole problem. Gentry's 2009 fix was to allow arbitrary depth by refreshing the ciphertext whenever the noise gets close to the limit.
Refresh the ciphertext without ever seeing the plaintext
Gentry's observation was that you can homomorphically evaluate the decryption function of the scheme itself. You take a noisy ciphertext. You encrypt the secret key under the public key to create an evaluation key, or evk. You give the server both the ciphertext and the evk. Then you ask the server to run the decryption function homomorphically, using the encrypted secret key inside the evk. The output is a new ciphertext of the same plaintext, with the noise reset back to a small value. The server never sees the secret key in the clear. The evk is itself a ciphertext. It also never sees the plaintext, because everything stays encrypted.
The trick is recursive but not circular. The decryption circuit is shallow enough to evaluate homomorphically using the somewhat-homomorphic scheme. The result is a fresh ciphertext. The whole scheme becomes fully homomorphic by repeating this refresh step whenever the noise budget is exhausted. The diagram below shows the loop.
In practice, this works at roughly three orders of magnitude of overhead. It is the most expensive operation in modern cryptography. It is also the only known way to do this kind of computation at all.
How it works
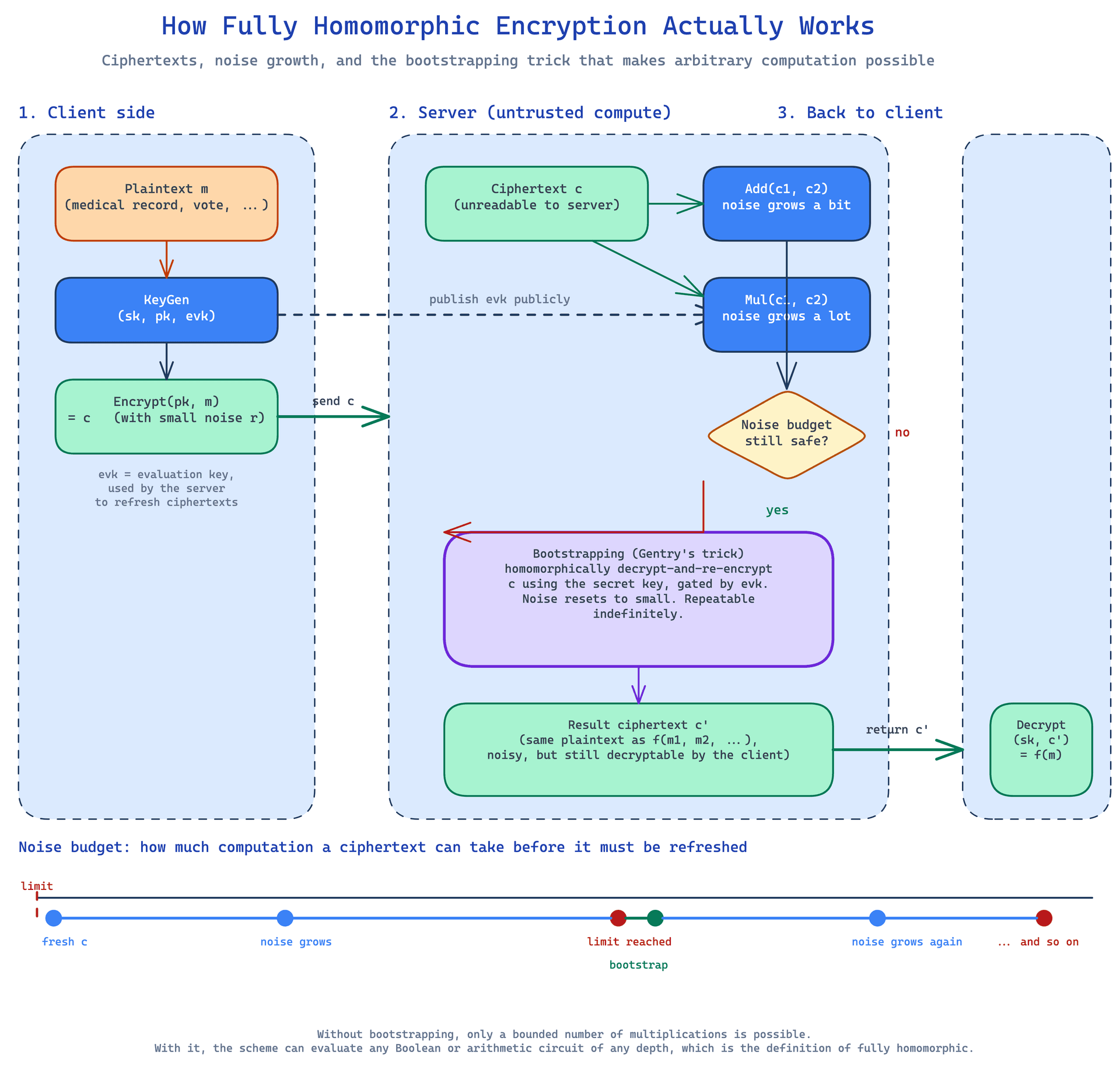
The diagram above shows the full loop. The client generates a keypair once: a secret key sk, a public key pk, and an evaluation key evk. The client keeps sk private. It publishes pk and evk. Then it encrypts the plaintext m into a ciphertext c with small noise, and sends c to the server. The server treats c as data. It runs add and mul circuits on it. Each operation grows the noise. The server checks the noise budget: if the noise is still safe, it continues. If the noise is close to the limit, the server runs the bootstrapping step. This homomorphically decrypts and re-encrypts c using the evk. The result is a fresh ciphertext c' that encrypts the same plaintext and has small noise. The server returns c' to the client. The client decrypts it with sk and gets the function's output f(m).
The bottom of the diagram is the noise budget over time. Fresh ciphertexts start with little noise. Each operation adds to it. Multiplications add a lot. When the noise hits the limit, the ciphertext is unsafe and has to be refreshed. The bootstrap step is the reset. After the reset, the noise is small again, and the next batch of operations can run. That is what "fully" buys you: as many refreshes as the circuit needs.
Where FHE is good, and where it hurts
FHE is real and it works. The state of the art, roughly:
- BGV and BFV handle exact integer arithmetic. They are the right choice for boolean circuits, integer sums, and applications where rounding matters.
- CKKS handles approximate real-number arithmetic. It is the right choice for floating-point machine learning inference and for statistical aggregation over many values. Its ciphertexts carry an inherent rounding error, which is fine for these applications.
- TFHE handles gate-by-gate bootstrapping. It is the right choice for evaluating small Boolean circuits very fast, and it is the engine behind several recent FHE compilers.
What FHE does badly is harder to dress up. Operations run thousands to millions of times slower than the plaintext equivalent. Ciphertexts are large, often kilobytes for a single bit or a small integer. Bootstrapping takes seconds even on a fast server. Making FHE usable in production means cutting this cost. Engineers batch operations. They choose the right scheme for the right problem. They push bootstrapping into a small number of well-understood primitives.
The honest version: FHE is no longer a research curiosity, and it is not a drop-in replacement for a normal CPU. It is a tool that fits specific shapes of problem, and the cost is real.
Privacy-preserving computation is starting to look plausible
If you accept the cost, the things you can build are unusual and useful:
- Outsourced computation on data the server cannot read. A hospital sends encrypted patient records to a cloud analytics provider. The provider computes aggregate statistics and returns encrypted results. The provider learns nothing about individual patients.
- Privacy-preserving machine learning. Inference on encrypted inputs is the most-discussed application. A user sends an encrypted feature vector to a model on someone else's server. The user gets an encrypted prediction back. They decrypt only the answer. The model owner never sees the inputs.
- Encrypted database queries. A database server processes queries over encrypted rows without ever seeing the underlying values. The cryptographic overhead is high, but for sensitive workloads it can be worth it.
- Electronic voting and sealed-bid auctions. The classic use case for homomorphic encryption since the 1990s, now with a fully homomorphic backend that supports arbitrary vote-tallying logic.
- Private set intersection and aggregation. The building blocks for ad-conversion measurement, joint fraud detection, and other things that require comparing data across organizations without revealing the data itself.
What makes FHE matter, beyond the application list, is the threat model it gives you. In the conventional model, whoever runs the server sees the data. With FHE, the server only runs the program. The data stays encrypted the whole time. This is a different kind of security guarantee than encryption at rest or in transit. The current generation of public cloud infrastructure is not designed to provide it.
Limits, risks, and what to watch next
FHE is not magic, and the limits show up in a few predictable places. Bootstrapping is the bottleneck. Schemes that minimize bootstrapping, like BGV, BFV, and CKKS, pay for it with larger parameters and slower operations. Schemes that bootstrap per gate, like TFHE, are fast for Boolean circuits but expensive for arithmetic. No single scheme wins on every workload. Parameter selection is more art than science. The wrong choice either slows the system down or breaks security. Production deployments must keep up with the lattice cryptanalysis literature, and that literature is still moving.
Implementation discipline matters because the cryptographic guarantee is about ciphertext contents, not about timing, memory access, or power. A poorly implemented FHE system can still leak plaintext through side channels. It needs the same care that goes into a TLS implementation. There is also no widely adopted FHE standard the way there is for AES or for the NIST post-quantum signatures. The Homomorphic Encryption Standardization consortium has been pushing an industry draft. There are early efforts in ISO and IETF. But the field is younger than the standardization ecosystem around it.
Deploying FHE in production means changing how the application is structured, how data is serialized, and how the pipeline is profiled. The skill set is not yet common in industry. Most teams that want to use FHE end up hiring or partnering with a small set of groups that have built the muscle.
The most useful thing to watch next year is FHE-specific accelerators. Both FPGA and ASIC variants need to move from research demos to production. A 10x to 100x speedup at the silicon level changes the math for almost every FHE application. Several startups are working on it. If those land, watch for the first widely-used privacy-preserving LLM inference service that actually uses FHE end to end.
Sources
- r/cryptography thread, "Wanna start learning FHE," May 2026: https://www.reddit.com/r/cryptography/comments/1t9kdn9/wanna_start_learning_fhe/
- Craig Gentry, "A Fully Homomorphic Encryption Scheme," Stanford dissertation / STOC 2009 (the original FHE construction)
- Z. Brakerski, C. Gentry, and V. Vaikuntanathan, "(Leveled) Fully Homomorphic Encryption without Bootstrapping," ITCS 2014 (BGV scheme)
- J. Fan and F. Vercauteren, "Somewhat Practical Fully Homomorphic Encryption," IACR ePrint 2012/144 (BFV scheme)
- J. H. Cheon, A. Kim, M. Kim, and Y. Song, "Homomorphic Encryption for Arithmetic of Approximate Numbers," ASIACRYPT 2017 (CKKS scheme)
- I. Chillotti, N. Gama, M. Georgieva, and M. Izabachène, "TFHE: Fast Fully Homomorphic Encryption over the Torus," Journal of Cryptology 2020 (TFHE scheme)
- O. Regev, "On Lattices, Learning with Errors, Random Linear Codes, and Cryptography," STOC 2005 (LWE hardness)
- V. Lyubashevsky, C. Peikert, and O. Regev, "On Ideal Lattices and Learning with Errors over Rings," EUROCRYPT 2010 (RLWE hardness)
- Homomorphic Encryption Standardization consortium: https://homomorphicencryption.org/
- Microsoft SEAL library documentation: https://github.com/microsoft/SEAL
- Google FHE Transpiler (XLS + FHE): https://google.github.io/xls/
- Zama Concrete / TFHE-rs library: https://www.zama.ai/
- OpenFHE library: https://www.openfhe.org/