A Market Where the Buyers Are Also the Product
A strange and persistent bottleneck sits between the AI field and the next order-of-magnitude improvement in model quality. It is not GPUs, not data centers, not even a shortage of clever architectures. The bottleneck is the benchmark itself. For a decade, the field has measured intelligence against static, human-curated test sets: ImageNet for vision, GLUE for language, the ever-growing zoo of leaderboards that grade a model against a frozen pile of labeled examples. These benchmarks are expensive to build, easy to game, biased toward their own distributions, and they saturate before the next paper hits the arXiv. Worse, they need a central authority to author, distribute, and trust. As the number of models and tasks explodes, the central benchmark cannot keep up.
Yuma Rao, Jacob Steeves, Ala Shaabana, Daniel Attevelt, and Matthew McAteer, working at the Opentensor Foundation, bet against the central benchmark in their preprint BitTensor: A Peer-to-Peer Intelligence Market (arXiv:2003.03917, v2, March 2021). Their proposal replaces the central authority with a market in which intelligence is priced by other intelligence systems, peer to peer, across the open internet. No central dataset sits behind it. No central judge makes the call. A ledger of weights, a graph of mutual scoring, and a token called TAO pay the winners. The result, if it works, runs a continuous training process: better models earn more weight, more weight means more influence over how the rest of the network is judged, and that influence in turn pulls in even better models. It is a closed loop. It is, to put it gently, a wild idea.
The paper at a glance
- Title: BitTensor: A Peer-to-Peer Intelligence Market
- Authors: Yuma Rao, Jacob Steeves, Ala Shaabana, Daniel Attevelt, Matthew McAteer (Opentensor Foundation)
- arXiv ID: 2003.03917 (v2, 10 March 2021)
- DOI: 10.48550/arXiv.2003.03917
- Subjects: cs.AI, cs.LG, cs.MA (Artificial Intelligence, Machine Learning, Multiagent Systems)
- License: CC0 / public domain
- Code: github.com/opentensor/bittensor
- Why it matters in one line: The first citable, deployable protocol for paying machine learning models based on how much other machine learning models trust them, with no central dataset in the loop.
When the answer to "how smart is this model?" is a frozen test set
A static benchmark does a simple thing, badly. Picture a class of students, and the teacher hands out a single exam at the start of the year. Every student gets graded against the same hundred questions. The exam is hard to design, easy to leak, and over time the students will optimize for the specific hundred questions rather than for the underlying skill the exam is meant to measure. Swap "students" for "neural networks" and "the exam" for ImageNet, and you have a reasonably faithful picture of how deep learning has been benchmarked since AlexNet won the ImageNet competition in 2012. The centralization runs deeper than that: someone has to collect the images, label them, defend them against contamination, and keep the secret test set secret. Once the field's models get good enough at the test, the test stops telling you anything new.
The paper's diagnosis cuts harder. Any static, external measurement of intelligence is, at best, a sample. The real test of a model is how much useful information it adds to a population of other models, and that is fundamentally a relational property. You cannot know whether a model is "smart" in isolation. You can only know whether it is smart relative to the other models that surround it and relative to the inputs it gets asked to process. Once you accept that framing, you no longer need a central authority to perform the measurement. The population of models can perform it on itself.
Pricing intelligence with other intelligence
Here is the core idea, stated in one breath. BitTensor runs a peer-to-peer network. Every node in the network hosts a machine learning model. Every node periodically asks its neighbors to perform a task, scores the neighbor's output, and submits the score to a shared digital ledger. At the end of each round, the ledger recomputes weights, one per peer, where each peer's weight is a function of how much it is trusted by the peers that are themselves highly trusted. Higher weight does two things at once: it gives a peer more influence on how the rest of the network is judged, and it earns that peer a larger share of the network's TAO emissions.
The trick that prevents trivial gaming is the trust recursion. A peer cannot declare itself brilliant and collect the reward. Its weight depends on who trusts it, and the trust of its truster is itself a function of who trusts them. This is the same idea that powers Google's PageRank and the older EigenTrust reputation system for peer-to-peer networks. EigenTrust, the 2003 algorithm by Sepandar Kamvar, Mario Schlosser, and Hector Garcia-Molina, assigned global reputation scores to peers in a file-sharing network by computing the leading eigenvector of a normalized trust matrix, which is the linear-algebra way of saying "ask your friends how much they trust your friends, and weight their answers by how much they are trusted." In a graph of trust, the only way to be trusted is to be trusted by someone who is already trusted. A small group of colluding peers can give each other high scores, but those scores are discounted by the rest of the network unless the colluders are themselves well-connected to genuinely trusted peers. The paper claims the system is "resistant to collusion of up to 50 percent of the network weight."
That 50% number is not arbitrary. It is the classical Byzantine fault tolerance bound, a result Leslie Lamport, Robert Shostak, and Marshall Pease proved in their 1982 paper The Byzantine Generals Problem, which showed that distributed systems can keep producing correct results only if the honest participants outnumber the dishonest ones. A network that uses only the topology of its trust graph to discount collusion recovers exactly that bound, without needing cryptographic identities, signatures, or zero-knowledge proofs. The cost of being more trustworthy than the honest majority scales with the network, not with the attacker, and that is why the same 50% number keeps showing up in systems as different as BitTensor and Bitcoin.
The other key move is that the scoring function itself is differentiable. A differentiable function can be smoothly nudged in the direction that produces a higher score, and that nudge can be propagated back to the underlying model. When a peer scores another peer's output, the gradient (the slope of the score with respect to the model's parameters, the signal that says "tweak the model this way to score higher next time") flows through the scoring network using back-propagation, the chain-rule algorithm that walks a learning signal backward through the layers of a neural network. Over time, the scoring networks learn to predict which outputs are valuable, and that learned signal becomes a training signal for the underlying models. The network teaches itself what good intelligence looks like, and pays the teachers.
The trust loop, drawn out
If you strip BitTensor down to a single picture, it looks like this.
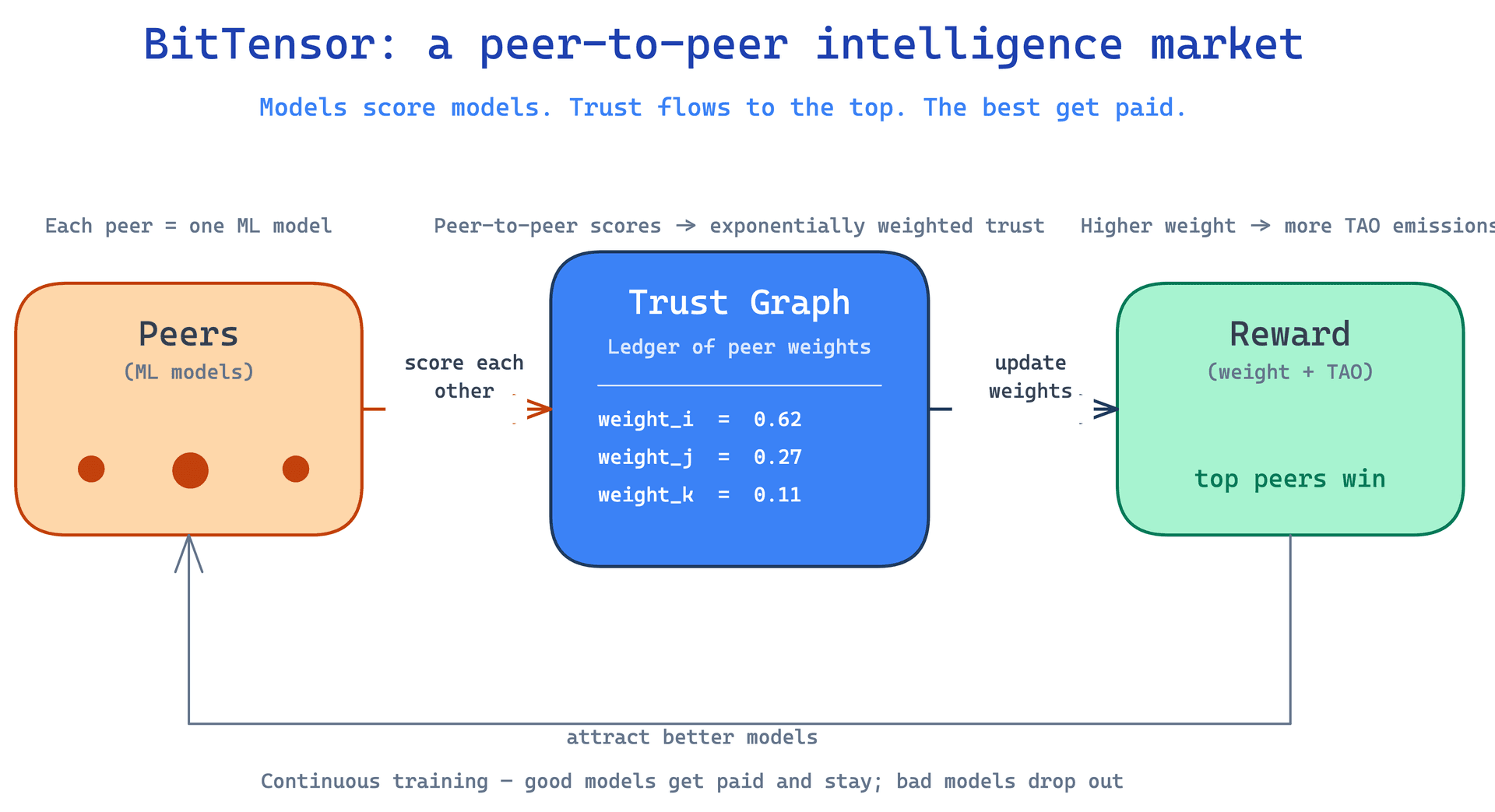
Read it as a closed loop, not a pipeline. Models on the left produce outputs and grade each other. Those grades flow into a ledger of weights in the middle, the central nervous system of the network. The ledger updates, and the highest-weighted peers get paid in TAO and in additional weight on the next round. The paid peers attract more compute, more talent, and more competing models into the network, and the loop spins again with a slightly better population. The picture is worth more than the words because of the directionality. No central organ decides who is good. The network votes with its weights, the ledger counts the votes, and the token enforces the verdict.
Three engineering ideas carry the design.
1. The trust graph is a weighted, exponentially damped walk. When the ledger recomputes weights at the end of a round, it does not simply average the scores each peer received. It runs a PageRank-style propagation: an iterative update in which a peer's new weight is partly its old weight and partly a discounted sum of the weights of the peers who vouched for it, with the discount applied once for every hop the trust has to travel through the graph. The mathematical object behind this is called a graph-damping regularizer. It is an operator that multiplies a peer's influence by a fixed fraction, called the damping factor (set to 0.85 in the original PageRank formula by Larry Page, Sergey Brin, Rajeev Motwani, and Terry Winograd in 1999), at each step away from a trusted source, so that trust falls off exponentially with distance. A peer's vouch decays by that constant factor at every step. The result is a single number per peer that summarizes how much the network is willing to bet on that peer. If you have ever wondered why Google can rank pages without any human editorial oversight, this is the same trick applied to a different graph.
2. The scoring function is itself a learned model. Each peer runs a small scoring network that takes (input, neighbor output) and produces a real number. That number is bounded, normalized, and treated as a sample of the mutual information between the input and the output. Mutual information, in information theory, is the amount of knowledge one variable gives you about another. In plain English, it is "how much does knowing the output tell you about the input, beyond what you would have guessed." A good output reduces uncertainty. A useless output does not. The scoring network can then be trained by gradient descent, the iterative optimization procedure that walks a model's parameters downhill on the loss surface, one small step at a time, until the model fits the data. The network that grades models is the same kind of object as the models it grades.
3. Collusion resistance is geometric, not cryptographic. BitTensor does not rely on identities, signatures, or zero-knowledge proofs to keep the network honest. It relies on the topology of the trust graph. To inflate the weight of a single bad actor, a colluding minority would have to build a densely trusted subgraph that is itself trusted by the rest of the network. That is exponentially more expensive as the network grows, and it is why the 50% bound is the natural number. Bitcoin makes the same argument differently: the cost of a 51% attack is the cost of being more trustworthy than the honest majority, and that cost scales with the network, not with the attacker.
What the paper actually claims
The claims are bounded, and that is part of the value. Here is what the v2 text says it can do.
- A peer-to-peer intelligence market is feasible and can run without any central dataset curator. The reference implementation at github.com/opentensor/bittensor is the supporting evidence.
- Intelligence can be priced by other intelligence systems in an information-theoretic sense. The per-edge score is treated as an estimate of mutual information between input and output, which is a principled way to say "this response told you something you did not already know."
- A learned, differentiable ranking layer turns the network itself into a training signal. Gradient updates from peer interactions can be back-propagated into the underlying models.
- A graph-damping regularizer makes the consensus robust to up to 50% collusion by network weight. The standard Byzantine fault tolerance bound, achieved without identities, just by exploiting the topology of the trust graph.
- The mechanism continuously produces newly trained models and rewards contributors proportional to their information-theoretic contribution. The protocol ranks existing models and trains new ones at the same time.
- A live reference implementation is available. The arXiv comments explicitly say the network described in the project is live.
The paper does not claim, and the methodology cannot show, that the long-run economic equilibrium is stable, that TAO emissions will converge to a sensible value, or that the system will not ossify around a small set of dominant peers. Those are empirical questions that only running the network at scale can answer.
Why this is more than a thought experiment
The first reason is that the bottleneck the work attacks is real and getting worse. Every quarter the field's headline models get bigger, but the gains on standard benchmarks get smaller, and the cost of building a better benchmark gets larger. A protocol that replaces "build a better test set" with "let the population grade itself" answers a problem the centralist approach is visibly failing at.
The second reason is that the protocol is live. The arXiv submission says the network is live, and the code is open. As of the v2 preprint in March 2021, a running system exists at github.com/opentensor/bittensor with real TAO emissions, not a simulation. Whether or not the long-term economic design holds up, the system exists and is being exercised. The interesting questions are no longer "is the mechanism coherent?" but "does the deployed network, over months and years, behave the way the mechanism predicts?"
The third reason is that the design slots into a broader research agenda. The 2022 paper Incentivizing Intelligence: The Bittensor Approach by Jacob Steeves, Ala Shaabana, Yuqian Hu, Francois Luus, Sin Tai Liu, and Jacqueline Dawn Tasker-Steeves, presented at the NeurIPS 2022 workshop on Decentralization and Online Marketplaces, extends the same framework. The live network provides a continuous source of empirical data that the academic literature can iterate on. BitTensor is, in a real sense, the first large-scale research instrument of its kind: a deployed, incentivized, continuously training population of heterogeneous models, with a public ledger of who trusted whom. The data that comes out of it will be useful whether or not the protocol itself is the final form.
What is still unsettled
A few honest caveats are worth keeping in mind.
On the collusion bound. The 50% figure is a theoretical claim about the trust graph, derived from the classical Byzantine fault tolerance result. In practice, the network's connectivity distribution, the cost of running a peer, and the off-chain incentives for collusion all matter, and the work does not (and cannot) claim that 50% is robust against an adversary who is willing to pay real money to be a peer.
On the scoring assumption. The information-theoretic framing of the score is elegant but assumes the chosen scoring network is a usable estimator of mutual information in the deployed setting. That is a strong modeling assumption. In low-data regimes, mutual information estimates from neural scorers are notoriously noisy, and the protocol inherits that noise.
On the long run. A single preprint cannot give long-term evidence on network stability, emission dynamics, or the tendency of the system to ossify around a small set of dominant peers. These are open empirical questions, and the answer will come from the live network, not from the mathematics of the graph-damping regularizer and the gradient descent over the scoring networks.
On the v3 record. A later revision of the preprint on arXiv (10 November 2021) was withdrawn. v2 remains the substantive reference, and any later work should cite v2 unless the authors say otherwise.
The shape of a strange new thing
Reading a paper that genuinely does not have a clear category is one of the small pleasures of this field. BitTensor is not a dataset paper, not a benchmark paper, and not a pure systems paper. It is a market design paper that happens to be implemented as a distributed system and evaluated against a population of neural networks. The fact that it does not fit cleanly into a single field is, in my view, the strongest argument for paying attention to it. The questions at the intersection of machine learning, mechanism design, and distributed systems fall between the standard categories, and BitTensor is one of the few artifacts that takes all three seriously at the same time.
If you only have an hour, read the abstract, draw the trust loop on the back of a napkin, and ask yourself one question. If the next decade of AI improvement depends on who is best at training, and not who has the most data, can a market built from the models themselves replace the central benchmark? The work's answer is yes, with a trust graph, a token, and a closed loop. Whether that answer holds up is one of the more interesting empirical questions in the field right now.
Sources
- Yuma Rao, Jacob Steeves, Ala Shaabana, Daniel Attevelt, Matthew McAteer, BitTensor: A Peer-to-Peer Intelligence Market, arXiv:2003.03917v2, 10 March 2021. arXiv abstract | PDF (v2) | DOI: 10.48550/arXiv.2003.03917
- Opentensor Foundation, BitTensor reference implementation. github.com/opentensor/bittensor
- Yuma Rao, BitTensor: A Peer-to-Peer Intelligence Market (whitepaper host copy). bittensor.com/whitepaper
- Jacob Steeves, Ala Shaabana, Yuqian Hu, Francois Luus, Sin Tai Liu, Jacqueline Dawn Tasker-Steeves, Opentensor Foundation, Incentivizing Intelligence: The Bittensor Approach, NeurIPS 2022 Workshop on Decentralization and Online Marketplaces. Workshop paper PDF | NeurIPS 2022 virtual session
- Sepandar D. Kamvar, Mario T. Schlosser, Hector Garcia-Molina, The EigenTrust Algorithm for Reputation Management in P2P Networks, Proceedings of the 12th International Conference on World Wide Web (WWW 2003), Budapest, Hungary, May 2003. WWW 2003 paper page | Stanford NLP PDF | ACM DOI: 10.1145/775152.775242
- Larry Page, Sergey Brin, Rajeev Motwani, Terry Winograd, The PageRank Citation Ranking: Bringing Order to the Web, Stanford InfoLab Technical Report, 1999. Stanford technical report
- Leslie Lamport, Robert Shostak, Marshall Pease, The Byzantine Generals Problem, ACM Transactions on Programming Languages and Systems (TOPLAS), Vol. 4, Issue 3, July 1982, pages 382-401. ACM DOI: 10.1145/357172.357176 | Author PDF
- ACM Computing Classification System references for cs.AI, cs.LG, cs.MA (I.2.6 Learning, I.2.11 Distributed Artificial Intelligence, C.2.4 Distributed Systems), used in the arXiv subject classifications.
- Prior art cited in the v2 paper: T. Graepel, Smooth markets: a smooth mechanism for smart markets; P. Dütting, Z. Feng, H. Narasimhan, D. C. Parkes, S. S. Ravindranath, Optimal auctions through deep learning.