The paper that deleted recurrence
In June 2017, eight researchers at Google Brain and Google Research submitted a paper whose title bordered on provocation. "Attention Is All You Need" was a direct challenge to the dominant paradigm of the time: recurrent neural networks, LSTMs, and the sequential computation they required. The paper argued that a state-of-the-art sequence model could be built using attention mechanisms alone. No recurrence. No convolutions. Just attention.
The architecture they introduced, the Transformer, now sits at the heart of nearly every major language model in circulation. BERT. GPT-3. T5. LLaMA. GPT-4, released last month. They all trace back to this single paper. What began as an experiment in machine translation has become the structural foundation for the current wave of artificial intelligence research.
The paper at a glance
- Publication / arXiv ID: 1706.03762
- Title: Attention Is All You Need
- Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
- Institutions: Google Brain, Google Research, University of Toronto
- Venue: NeurIPS 2017
- Submission date: June 12, 2017
- Source: arXiv:1706.03762
The sequential bottleneck that slowed everything down
By 2017, recurrent neural networks and their gated variants, LSTMs and GRUs, had been the default architecture for sequence modeling for years. They worked for machine translation, language modeling, speech recognition, and more. The idea was straightforward: process a sequence one token at a time, maintaining a hidden state that accumulates information from everything seen so far. The encoder reads the input left to right, updating its hidden state at each step. The decoder generates the output sequence one token at a time, using the encoder's final state as a starting point.
The problem was structural. Because each hidden state depends on the previous one, you cannot parallelize computation within a single training example. If your sequence has a hundred tokens, you need a hundred sequential steps. On GPUs, which excel at parallel matrix operations, this is like trying to paint a highway with a single brush. You can batch multiple sequences together, but within each sequence, you are stuck.
Long-range dependencies made things worse. In an RNN, the signal from the first token travels through every hidden state to reach the last token. For long sentences, the gradient path grows linearly with sequence length. Information gets diluted. Vanishing gradients become a real problem. Attention mechanisms, introduced by Bahdanau and others, helped by letting the decoder look directly at encoder states. But they were still bolted onto a recurrent backbone. The sequential bottleneck remained.
What if we just got rid of recurrence entirely?
Jakob Uszkoreit, one of the authors, proposed replacing RNNs with self-attention. The idea sounds almost too simple. Instead of processing a sequence token by token, let every token attend to every other token directly, all at once. The path length between any two positions becomes one. The number of sequential operations per layer drops to a constant.
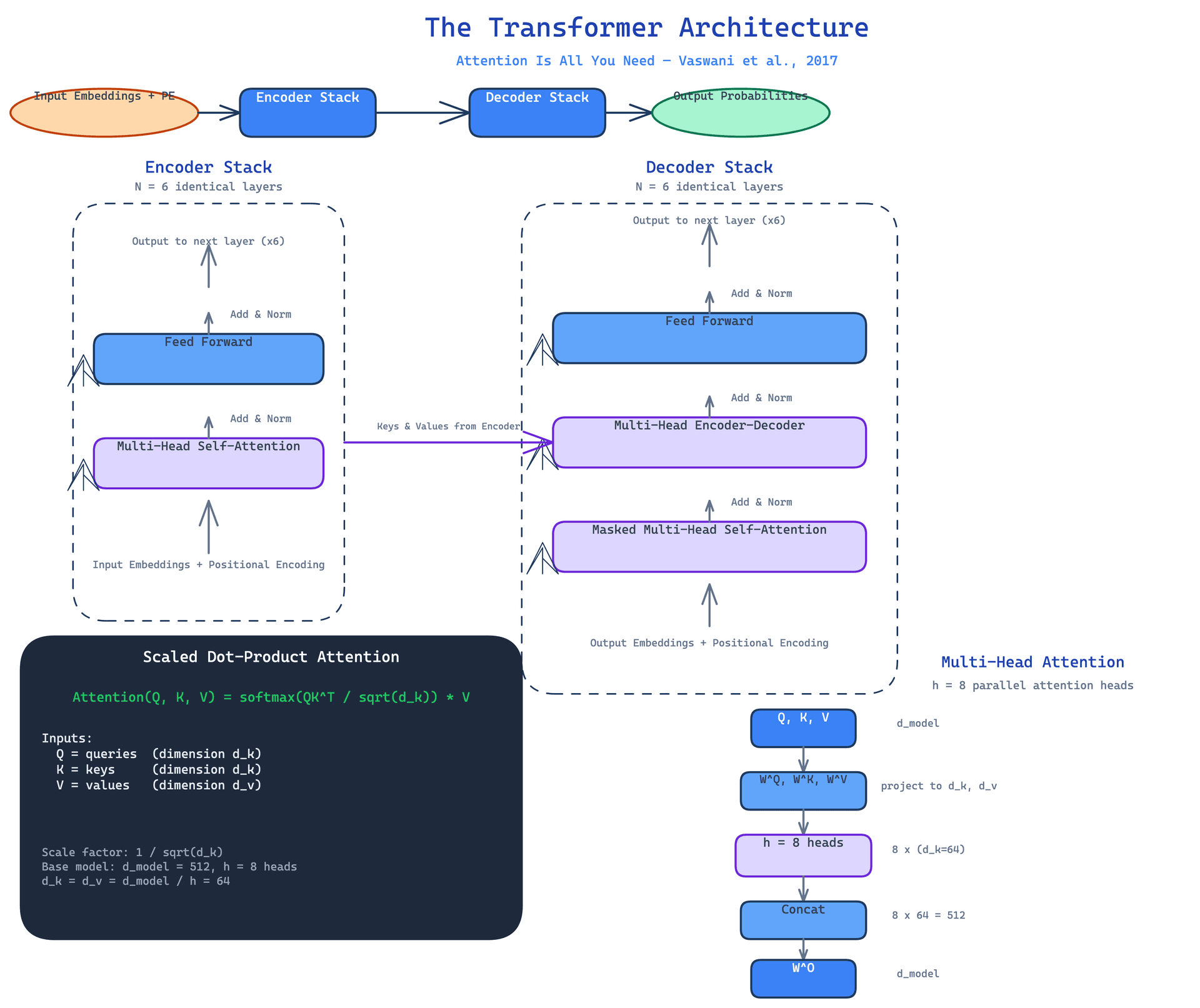
The authors called the resulting architecture the Transformer. It keeps the encoder-decoder structure that sequence-to-sequence models use, but replaces the recurrent layers with two simpler building blocks: multi-head self-attention and position-wise feed-forward networks. Each layer adds residual connections and layer normalization around these sub-layers. The result is a stack of six identical layers for both encoder and decoder, with no recurrence anywhere.
The insight was not simply to use attention, but to configure it precisely. A single attention head averages too much. Multiple heads, running in parallel on different learned projections, let the model attend to different representation subspaces simultaneously. A scaling factor of one over the square root of the key dimension keeps the softmax stable. Positional encodings, added to the input embeddings, inject sequence order information without requiring sequential processing.
How it works: the architecture in detail
The Transformer follows a familiar encoder-decoder shape, but the internals are different from its predecessors.
The encoder stack. The encoder maps an input sequence to a sequence of continuous representations. It is a stack of six identical layers. Each layer has two sub-layers. The first is multi-head self-attention, where every position in the sequence can attend to every other position. The second is a position-wise fully connected feed-forward network. Around each sub-layer, the authors add a residual connection followed by layer normalization. Every sub-layer and embedding produces outputs of dimension 512.
The decoder stack. The decoder is also six identical layers, but with a third sub-layer. The first is masked multi-head self-attention, where positions can only attend to previous positions (and themselves) to preserve the auto-regressive property. The second is multi-head encoder-decoder attention, where queries come from the decoder and keys and values come from the encoder output. The third is another feed-forward network. Residual connections and layer normalization wrap each sub-layer.
Scaled dot-product attention. The attention function itself is compact. Given queries Q, keys K, and values V, the output is:
The dot products are scaled by one over the square root of the key dimension to prevent the softmax from saturating when is large. In practice, this is computed for all queries simultaneously using matrix multiplication, which maps directly to highly optimized GPU operations.
Multi-head attention. Instead of a single attention function, the model uses eight parallel heads. For each head, the queries, keys, and values are projected to 64-dimensional spaces. Attention runs in parallel on all eight projections. The outputs are concatenated and projected once more. The total computational cost is similar to single-head attention with full dimensionality, but the expressiveness is greater.
Positional encodings. Since there is no recurrence, the model has no inherent sense of token order. The authors add sinusoidal positional encodings to the input embeddings. Each dimension corresponds to a sinusoid with a different wavelength, forming a geometric progression. The authors chose this over learned embeddings because it allows the model to extrapolate to longer sequences than it saw during training.
The numbers that got everyone's attention
The authors trained their models on standard WMT 2014 datasets using eight NVIDIA P100 GPUs. The results were striking.
On English-to-German translation (newstest2014), the big Transformer achieved 28.4 BLEU. That improved over the existing best results, including ensemble models, by over 2.0 BLEU. On English-to-French translation, the big single model hit 41.0 BLEU, and the ensemble reached 41.8 BLEU, establishing a new state of the art. The entire training run took 3.5 days. Prior top models required training costs orders of magnitude higher.
The base model, trained in just 12 hours, also outperformed nearly all previously published individual models and ensembles.
The authors also tested generalization beyond translation. Applied to English constituency parsing on the Penn Treebank, the Transformer outperformed the BerkeleyParser even with limited training data (40K sentences). With no task-specific tuning, it performed competitively with the best reported results. This showed the architecture was not limited to translation.
Ablation studies confirmed the importance of each design choice. Dropping from eight attention heads to one hurt performance by about one BLEU point. Removing dropout caused clear overfitting. Label smoothing provided small but consistent gains. The scaling factor in the attention mechanism proved necessary for stable training at larger dimensions.
From machine translation to GPT-4: why this architecture took over
When "Attention Is All You Need" first appeared, the machine learning community treated it primarily as a machine translation result. The broader implications took time to sink in. But the properties that made it good for translation made it good for almost everything else.
Parallelization was the immediate win. Training a Transformer on modern hardware is far more efficient than training an RNN of comparable capacity. The matrix multiplications that dominate Transformer computation map cleanly to GPU tensor cores. Researchers could train larger models on larger datasets, which was the key ingredient for the scaling laws that now define the field.
The constant path length made long-range dependencies tractable. In an RNN, the first word of a paragraph and the last word are separated by a path proportional to the paragraph length. In a Transformer, they are one attention layer apart. This property is essential for modeling long documents and coherent dialogue. It also helps with structured reasoning tasks where distant tokens need to interact.
In 2018, BERT showed that Transformer encoders could be pre-trained on massive unlabeled text and then fine-tuned for a wide range of downstream tasks. In 2019, GPT-2 demonstrated that large Transformer decoders could generate coherent, contextually relevant text. GPT-3, released in 2020, pushed this to 175 billion parameters and showed few-shot learning capabilities that drew considerable attention.
In late 2022, ChatGPT brought these capabilities to a general audience. In March 2023, GPT-4 raised the bar again on reasoning, code generation, and multimodal tasks. Every one of these models uses the Transformer architecture. The six-layer stack from the original paper has been scaled up by orders of magnitude, but the core mechanism, scaled dot-product attention, remains unchanged.
The quadratic cost nobody talks about
The Transformer is not without limitations, and the authors were upfront about them.
Self-attention has complexity per layer. For long sequences, the quadratic cost in sequence length becomes prohibitive. A document with 4,000 tokens requires 16 times more computation than one with 1,000 tokens. The authors noted this explicitly and suggested investigating restricted attention, where each position only attends to a local neighborhood, as a direction for future work.
The averaging in attention-weighted positions also reduces effective resolution. Multi-head attention mitigates this, but the tradeoff exists. Individual attention distributions can become diffuse, and the model may struggle to focus precisely when many positions compete for attention weight.
Training requires careful optimization. The learning rate schedule needs a warmup period (4,000 steps in the original work) before decaying. Dropout and label smoothing are necessary to prevent overfitting. These are not insurmountable hurdles, but they make the model less forgiving than a standard RNN setup.
Positional encodings remain an active area of exploration. The sinusoidal version works well, but learned positional embeddings perform nearly identically in the authors' experiments. For very long sequences, neither approach is clearly superior. Researchers have since proposed rotary embeddings, ALiBi, and other alternatives, each with their own tradeoffs.
The authors closed the paper by expressing excitement about applying attention-based models to other tasks and modalities. They specifically mentioned investigating local, restricted attention for large inputs and outputs such as images, audio, and video. In 2023, that research agenda is very much alive. Vision Transformers, speech models, and multimodal systems are all exploring variants of the same core idea.
Sources
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30. arXiv:1706.03762
- Tensor2Tensor implementation: https://github.com/tensorflow/tensor2tensor